from movement import sample_dataDownloading data from 'https://gin.g-node.org/neuroinformatics/movement-test-data/raw/master/metadata.yaml' to file '/home/runner/.movement/data/temp_metadata.yaml'.In this tutorial, we will introduce the movement package and walk through parts of its documentation.
You will be given a set of exercises to complete—using movement to analyse the pose tracks you’ve generated in Chapter 3 or any other tracking data you may have access to.
If you are following along this chapter on your own computer, make sure to run all code snippets with the animals-in-motion-env environment activated (see prerequisites A.3.3). This also applies to launching the movement graphical user interface (Section 4.4) and running movement examples as Jupyter notebooks (Section 4.5 and Section 4.6).
In chapters 1 and 2 we saw how the rise of deep learning-based markerless motion tracking tools is transforming the study of animal behaviour.
In Chapter 3 we dove deeper into SLEAP, a popular package for pose estimation and tracking. We saw how SLEAP and similar tools—like DeepLabCut and LightningPose—detect the positions of user-defined keypoints in video frames, group the keypoints into poses, and connect their identities across time into sequential collections we call pose tracks.
The extraction of pose tracks is often just the beginning of the analysis. Researchers use these tracks to investigate various aspects of animal behaviour, such as kinematics, spatial navigation, social interactions, etc. Typically, these analyses involve custom, project-specific scripts that are hard to reuse across different projects and are rarely maintained after the project’s conclusion.
In response to these challenges, we saw the need for a versatile and easy-to-use toolbox that is compatible with a range of ML-based motion tracking frameworks and supports interactive data exploration and analysis. That’s where movement comes in. We started building in early 2023 to answer the question: what can I do now with these tracks?
movementaims to facilitate the study of animal behaviour by providing a consistent, modular interface for analysing motion tracks, enabling steps such as data cleaning, visualisation, and motion quantification.
See movement’s mission and scope statement for more details.
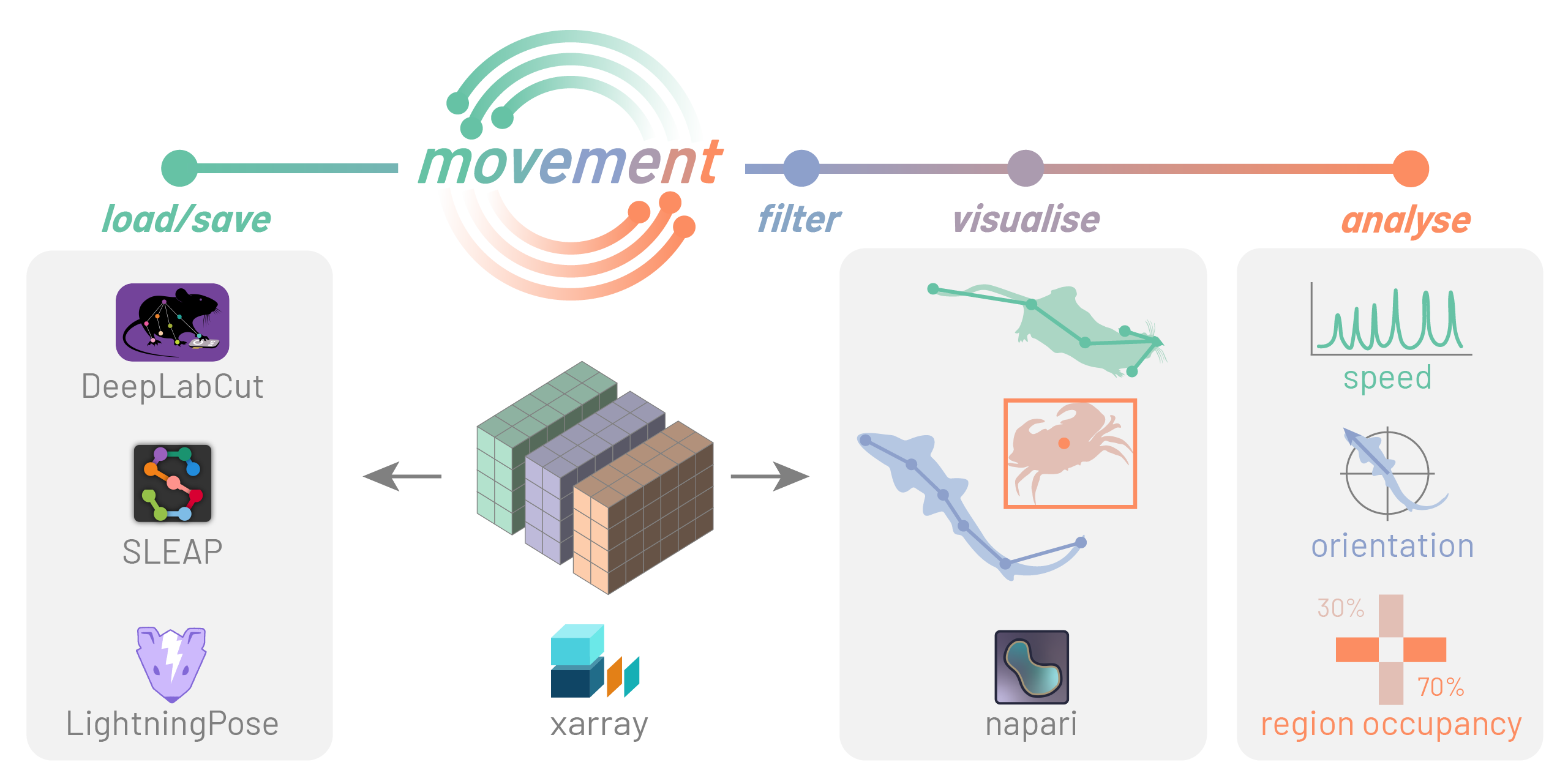
movement package
movement aims to support all popular animal tracking frameworks and file formats, in 2D and 3D, tracking single or multiple animals of any species.
To achieve this level of versatility, we had to identify what’s common across the outputs of motion tracking tools and how we can represent them in a standardised way.
What we came up with takes the form of collections of multi-dimensional arrays—an xarray.Dataset object. Each array within a dataset is an xarray.DataArray object holding different aspects of the collected data (position, time, confidence scores…). You can think of an xarray.DataArray as a multi-dimensional numpy.ndarray with pandas-style indexing and labelling.
This may sound complicated but fear not, we’ll build some understanding by exploring some example datasets that are included in the movement package.
from movement import sample_dataDownloading data from 'https://gin.g-node.org/neuroinformatics/movement-test-data/raw/master/metadata.yaml' to file '/home/runner/.movement/data/temp_metadata.yaml'.First, let’s see how movement represents pose tracks, like the ones we get with SLEAP.
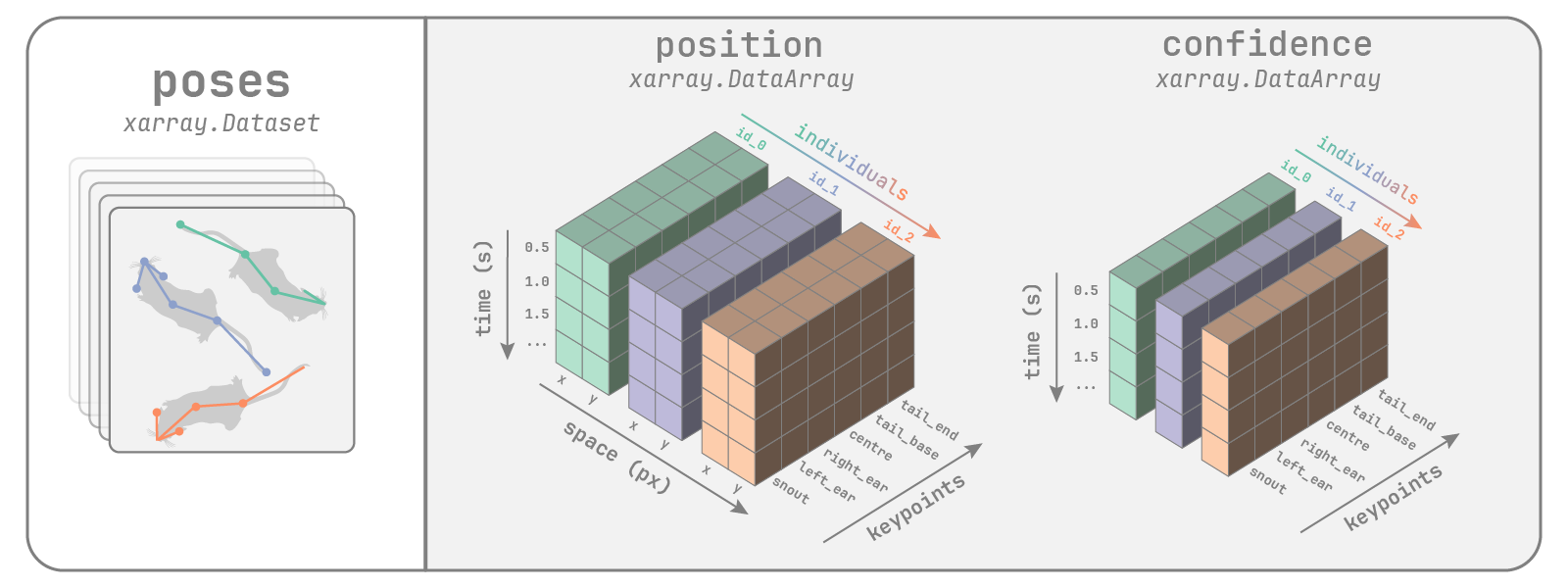
movement poses dataset
Let’s load an example dataset and explore its contents.
poses_ds = sample_data.fetch_dataset("SLEAP_two-mice_octagon.analysis.h5")
poses_dsDownloading file 'frames/two-mice_octagon_frame-10sec.png' from 'https://gin.g-node.org/neuroinformatics/movement-test-data/raw/master/frames/two-mice_octagon_frame-10sec.png' to '/home/runner/.movement/data'.
0.00B [00:00, ?B/s]9.22kB [00:00, 62.6kB/s]49.2kB [00:00, 183kB/s] 73.7kB [00:00, 137kB/s]156kB [00:00, 276kB/s] 213kB [00:00, 272kB/s]314kB [00:01, 389kB/s]360kB [00:01, 364kB/s]401kB [00:01, 337kB/s]459kB [00:01, 350kB/s]508kB [00:01, 343kB/s]0.00B [00:00, ?B/s] 0.00B [00:00, ?B/s]
Downloading file 'poses/SLEAP_two-mice_octagon.analysis.h5' from 'https://gin.g-node.org/neuroinformatics/movement-test-data/raw/master/poses/SLEAP_two-mice_octagon.analysis.h5' to '/home/runner/.movement/data'.
0.00B [00:00, ?B/s]17.4kB [00:00, 117kB/s]43.0kB [00:00, 148kB/s]75.8kB [00:00, 143kB/s]146kB [00:00, 190kB/s] 180kB [00:00, 199kB/s]247kB [00:01, 266kB/s]290kB [00:01, 272kB/s]342kB [00:01, 294kB/s]391kB [00:01, 303kB/s]449kB [00:01, 326kB/s]499kB [00:01, 328kB/s]550kB [00:02, 332kB/s]609kB [00:02, 350kB/s]663kB [00:02, 383kB/s]702kB [00:02, 378kB/s]744kB [00:02, 367kB/s]782kB [00:02, 362kB/s]828kB [00:02, 379kB/s]867kB [00:02, 372kB/s]919kB [00:02, 385kB/s]957kB [00:03, 376kB/s]998kB [00:03, 377kB/s]1.04MB [00:03, 367kB/s]1.09MB [00:03, 363kB/s]1.14MB [00:03, 379kB/s]1.18MB [00:03, 292kB/s]1.24MB [00:03, 353kB/s]1.28MB [00:04, 342kB/s]1.32MB [00:04, 340kB/s]0.00B [00:00, ?B/s] 0.00B [00:00, ?B/s]<xarray.Dataset> Size: 2MB
Dimensions: (time: 9000, space: 2, keypoints: 7, individuals: 2)
Coordinates: (4)
Data variables:
position (time, space, keypoints, individuals) float32 1MB 796.5 ... nan
confidence (time, keypoints, individuals) float32 504kB 0.9292 ... 0.0
Attributes: (6)movement also supports datasets that consist of bounding boxes, like the ones we would get if we performed object detection on a video, followed by tracking identities across time.
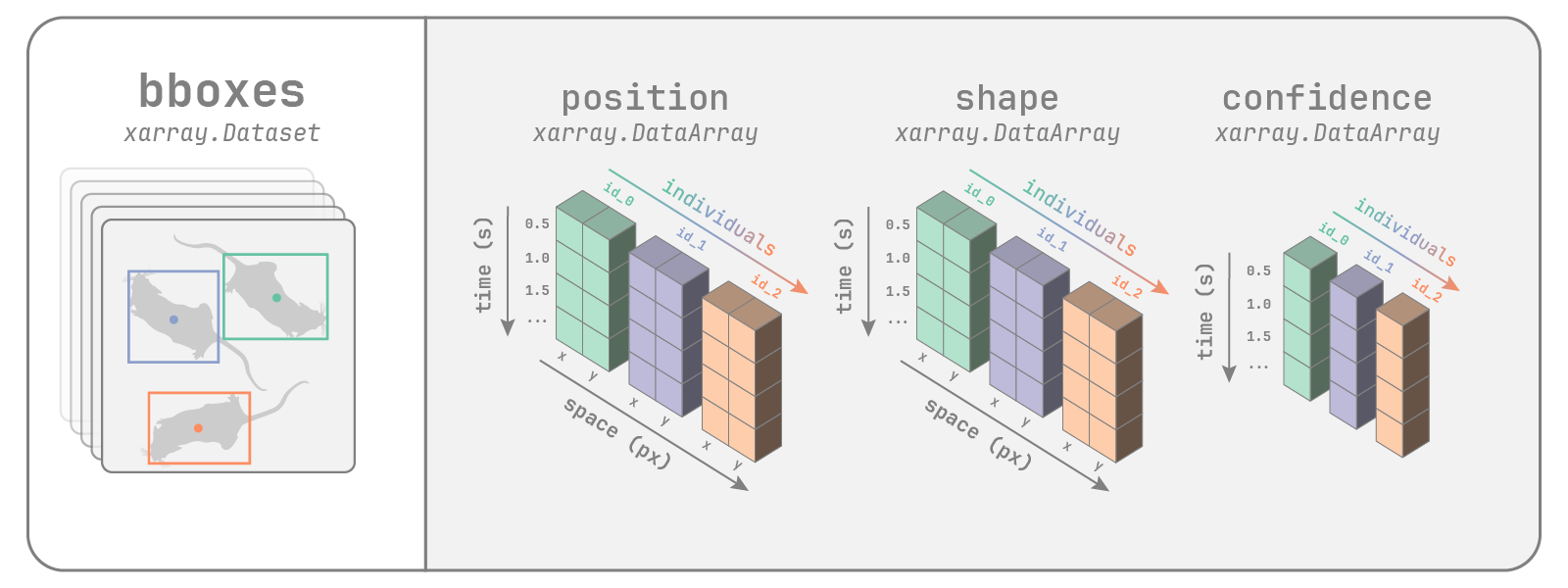
movement bounding boxes dataset
bboxes_ds = sample_data.fetch_dataset(
"VIA_single-crab_MOCA-crab-1_linear-interp.csv"
)bboxes_ds<xarray.Dataset> Size: 8kB
Dimensions: (time: 168, space: 2, individuals: 1)
Coordinates: (3)
Data variables:
position (time, space, individuals) float64 3kB 1.118e+03 ... 401.9
shape (time, space, individuals) float64 3kB 320.1 153.2 ... 120.1
confidence (time, individuals) float64 1kB nan nan nan nan ... nan nan nan
Attributes: (6)movement’s approach? What kinds of data cannot be accommodated?See the documentation on movement datasets for more details on movement data structures.
Since movement represents motion tracking data as xarray objects, we can use all of xarray’s intuitive interface and rich built-in functionalities for data manipulation and analysis.
Accessing data variables and attributes (metadata) is straightforward:
print(f"Source software: {poses_ds.source_software}")
print(f"Frames per second: {poses_ds.fps}")
poses_ds.positionSource software: SLEAP
Frames per second: 50.0<xarray.DataArray 'position' (time: 9000, space: 2, keypoints: 7, individuals: 2)> Size: 1MB 796.5 724.5 812.8 721.0 816.9 704.9 821.1 ... 572.4 116.7 552.8 124.5 539.9 nan Coordinates: (4)
We can select a subset of data along any dimension in a variety of ways: by integer index (order) or coordinate label.
# First individual, first time point
poses_ds.position.isel(individuals=0, time=0)
# 0-10 seconds, two specific keypoints
poses_ds.position.sel(time=slice(0, 10), keypoints=["EarLeft", "EarRight"])<xarray.DataArray 'position' (time: 501, space: 2, keypoints: 2, individuals: 2)> Size: 16kB 812.8 721.0 816.9 704.9 853.0 984.8 ... 359.9 340.0 852.2 811.8 835.9 800.6 Coordinates: (4)
We can also do all sorts of computations on the data, along any dimension.
# Each point's median confidence score across time
poses_ds.confidence.median(dim="time")
# Take the block mean for every 10 frames.
poses_ds.position.coarsen(time=10, boundary="trim").mean()<xarray.DataArray 'position' (time: 900, space: 2, keypoints: 7, individuals: 2)> Size: 101kB 757.0 733.4 771.6 725.0 779.1 711.3 ... 553.9 116.5 544.9 124.2 541.0 128.6 Coordinates: (4)
xarray also provides a rich set of built-in plotting methods for visualising the data.
from matplotlib import pyplot as plt
tail_base_pos = poses_ds.sel(keypoints="TailBase").position
tail_base_pos.plot.line(
x="time", row="individuals", hue="space", aspect=2, size=2.5
)
plt.show()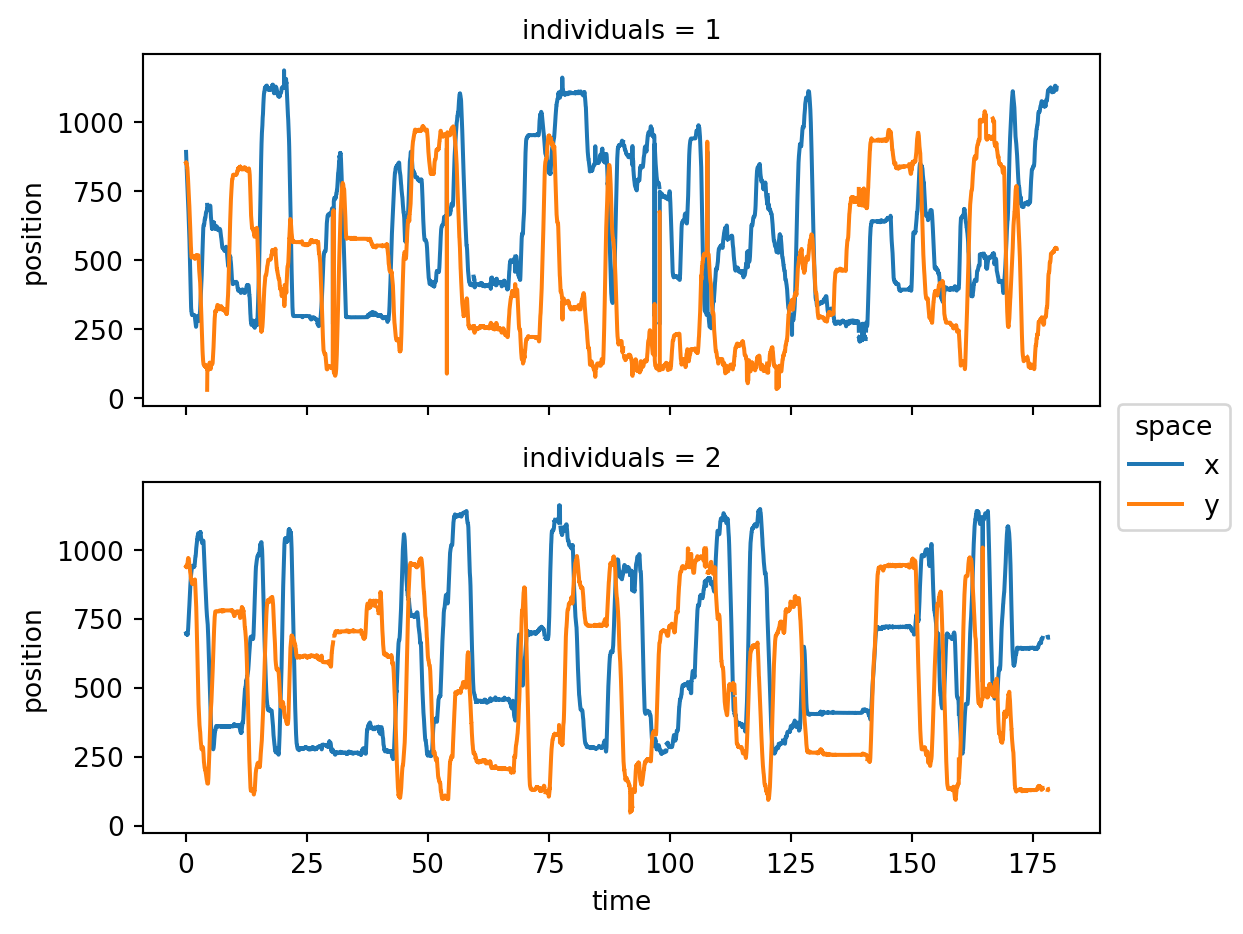
You can also combine those with matplotlib figures.
colors = plt.cm.tab10.colors
fig, ax = plt.subplots()
for kp, color in zip(poses_ds.keypoints, colors):
data = poses_ds.confidence.sel(keypoints=kp)
data.plot.hist(
bins=50, histtype="step", density=True, ax=ax, color=color, label=kp
)
ax.set_ylabel("Density")
ax.set_title("Confidence histograms per keypoint")
plt.legend()
plt.show()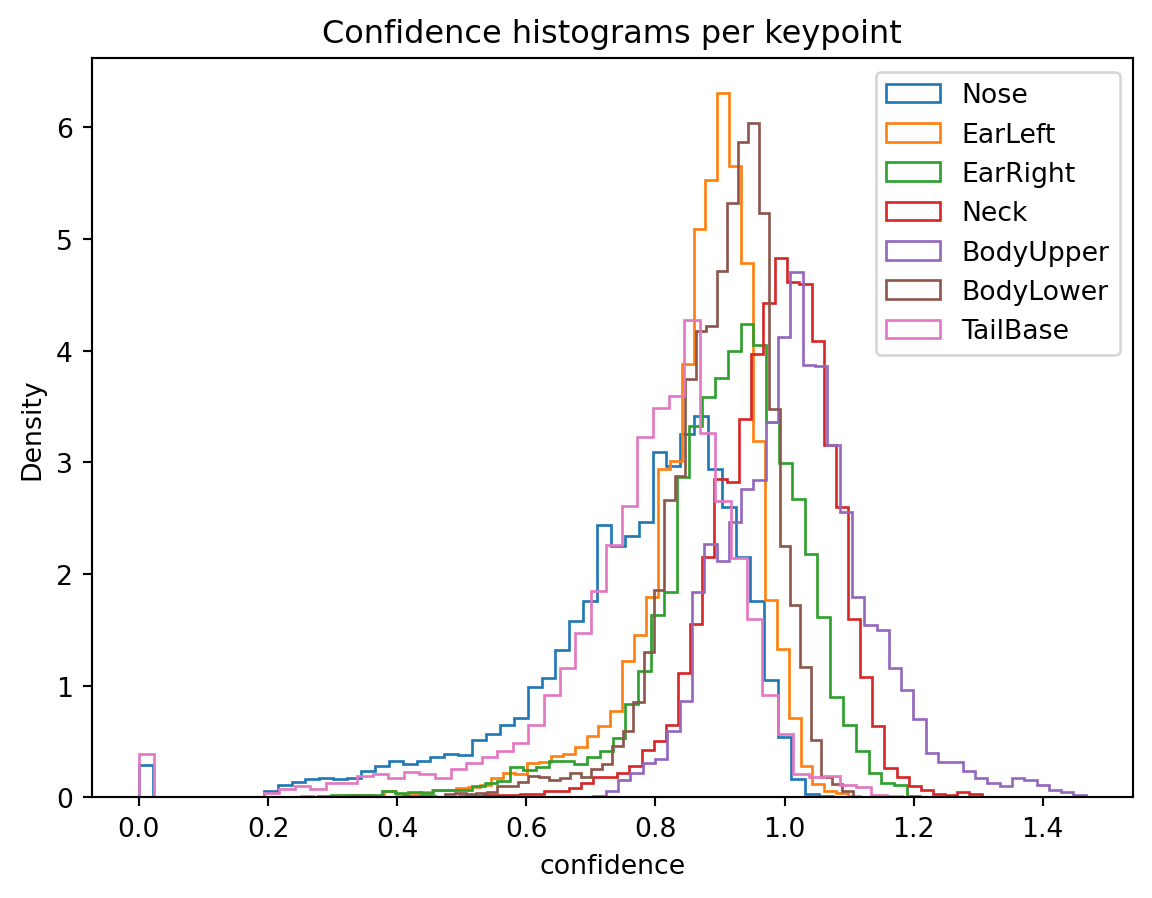
You may also want to export date to structures you may be more familiar with, such as Pandas DataFrames or NumPy arrays.
Export the position data array as a pandas DataFrame:
position_df = poses_ds.position.to_dataframe(
dim_order=["time", "individuals", "keypoints", "space"]
)
position_df.head()| position | ||||
|---|---|---|---|---|
| time | individuals | keypoints | space | |
| 0.0 | 1 | Nose | x | 796.473145 |
| y | 843.941101 | |||
| EarLeft | x | 812.779114 | ||
| y | 853.027039 | |||
| EarRight | x | 816.932190 |
Export data variables or coordinates as numpy arrays:
position_array = poses_ds.position.values
print(f"Position array shape: {position_array.shape}")
time_array = poses_ds.time.values
print(f"Time array shape: {time_array.shape}")Position array shape: (9000, 2, 7, 2)
Time array shape: (9000,)The .to_numpy() method is equivalent to .values and is more explicit. It may make the code easier to read.
For saving datasets to disk, we recommend leveraging xarray’s built-in support for the netCDF file format.
import xarray as xr
# To save a dataset to disk
poses_ds.to_netcdf("poses_ds.nc")
# To load the dataset back from memory
poses_ds = xr.open_dataset("poses_ds.nc")As stated above, our goal with movement is to enable pipelines that are input-agnostic, meaning they are not tied to a specific motion tracking tool or data format. Therefore, movement offers input/output functions that facilitate data flows between various motion tracking frameworks and movement’s own xarray data structure.
Please refer to the Input/Output section of the movement documentation for more details, including a full list of supported formats.
movement dataset. Alternatively, feel free to work with the CalMS21/mouse044_task1_annotator1.slp file from Dropbox (refer to prerequisites A.4) or any of movement’s sample datasets.Bonus: Overlay the centroid trajectory (task 4) on top of a frame extracted from the video. You may find inspiration in the “Pupil tracking” example.
Useful resources:
Loading pose tracks from a file:
from pathlib import Path
from movement.io import load_poses
file_name = "mouse044_task1_annotator1.slp"
file_path = Path.home() / ".movement" / "CalMS21" / file_name
ds = load_poses.from_file(file_path, source_software="SLEAP", fps=30)
ds<xarray.Dataset> Size: 598kB
Dimensions: (time: 3394, space: 2, keypoints: 7, individuals: 2)
Coordinates: (4)
Data variables:
position (time, space, keypoints, individuals) float32 380kB 854.4 .....
confidence (time, keypoints, individuals) float32 190kB nan nan ... nan
Attributes: (5)Computing the minimum and maximum x,y positions:
for space_coord in ["x", "y"]:
min_pos = ds.position.sel(space=space_coord).min().values
max_pos = ds.position.sel(space=space_coord).max().values
print(f"Min-Max {space_coord} positions: {min_pos:.2f}-{max_pos:.2f}")Min-Max x positions: 83.79-988.99
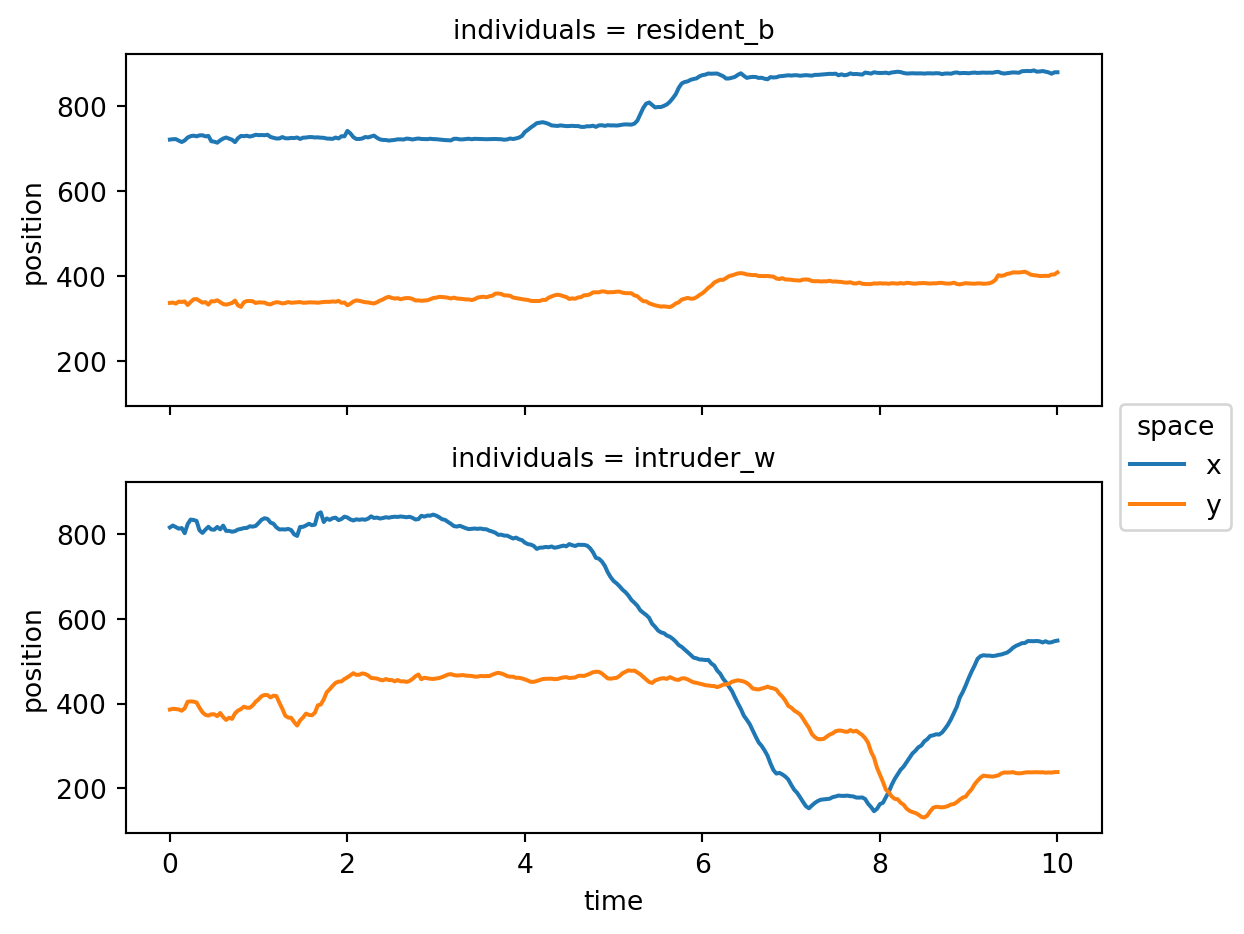
Min-Max y positions: 64.72-563.30Plotting the x,y positions of a certain keypoint across time, within a narrow time window:
ds.position.sel(keypoints="tail_base", time=slice(0, 10)).plot.line(
x="time", row="individuals", hue="space", aspect=2, size=2.5
)
Plotting the centroid trajectory:
from movement.plots import plot_centroid_trajectory
fig, ax = plt.subplots(figsize=(8, 4))
plot_centroid_trajectory(ds.position, individual="resident_b", ax=ax)
plt.show()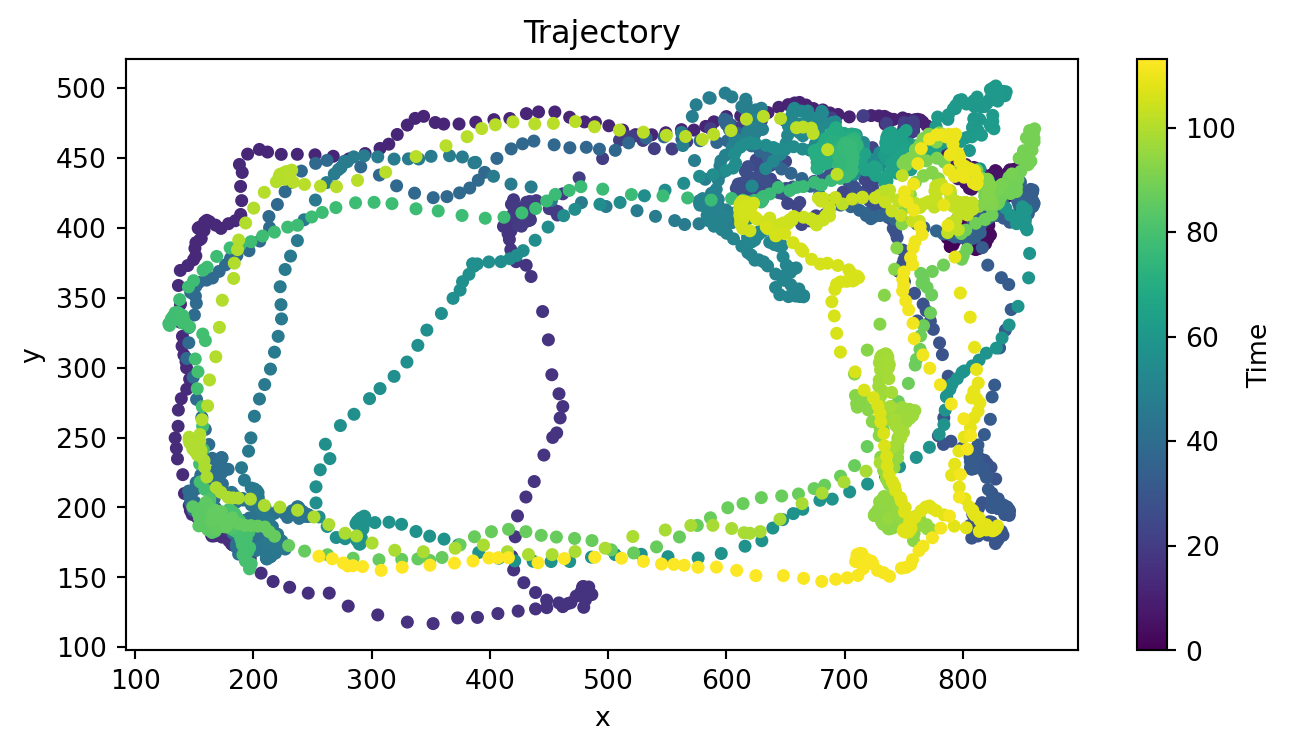
As a bonus, we can also overlay that trajectory on top of a video frame.
import sleap_io as sio
video_path = Path.home() / ".movement" / "CalMS21" / "mouse044_task1_annotator1.mp4"
video = sio.load_video(video_path)
n_frames, height, width, channels = video.shape
print(f"Number of frames: {n_frames}")
print(f"Frame size: {width}x{height}")
print(f"Number of channels: {channels}\n")
# Extract the first frame to use as background
background = video[0]
fig, ax = plt.subplots(figsize=(8, 4))
# Plot the first video frame
ax.imshow(background, cmap="gray")
# Plot the centroid trajectory
plot_centroid_trajectory(
ds.position, individual="resident_b", ax=ax, alpha=0.75, s=5,
)
plt.show()Number of frames: 3394
Frame size: 1024x570
Number of channels: 3
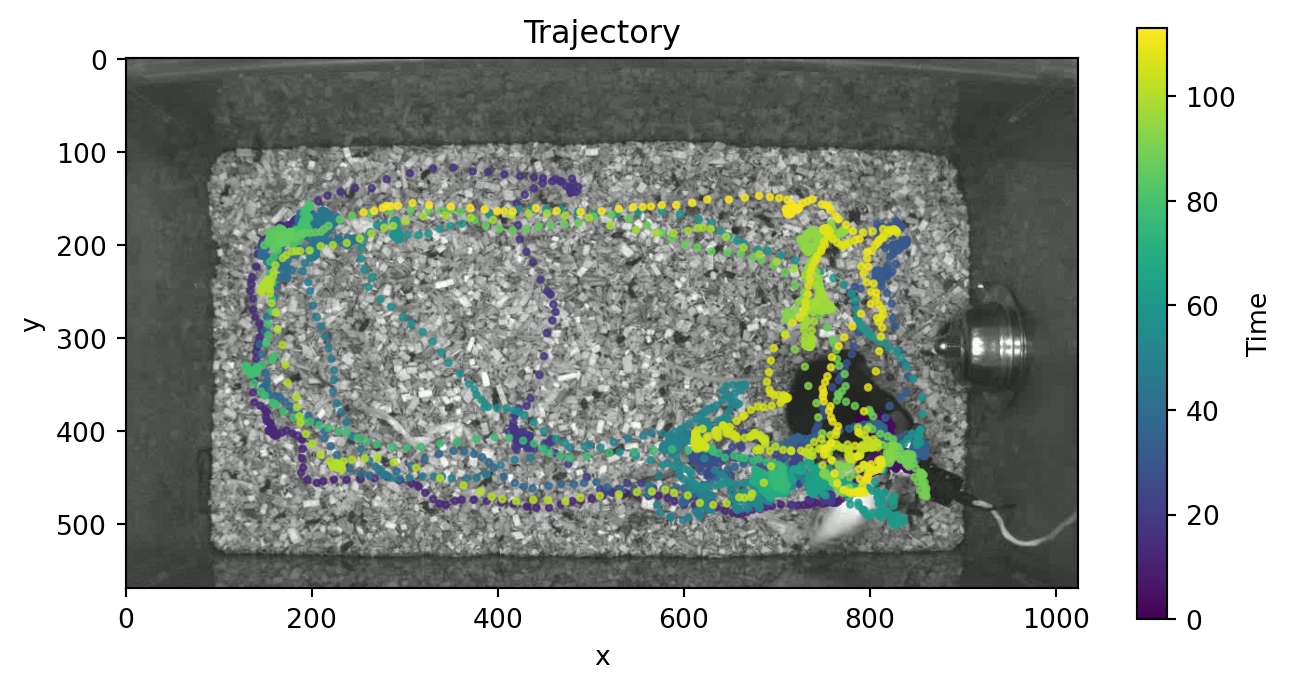
The movement graphical user interface (GUI), powered by our custom plugin for napari, makes it easy to view and explore motion tracks. Currently, you can use it to visualise 2D movement datasets as points, tracks, and rectangular bounding boxes (if defined) overlaid on video frames.
We’ll first demonstrate how the GUI works by using it to explore the CalMS21 dataset and some of the sample data we can fetch with movement.
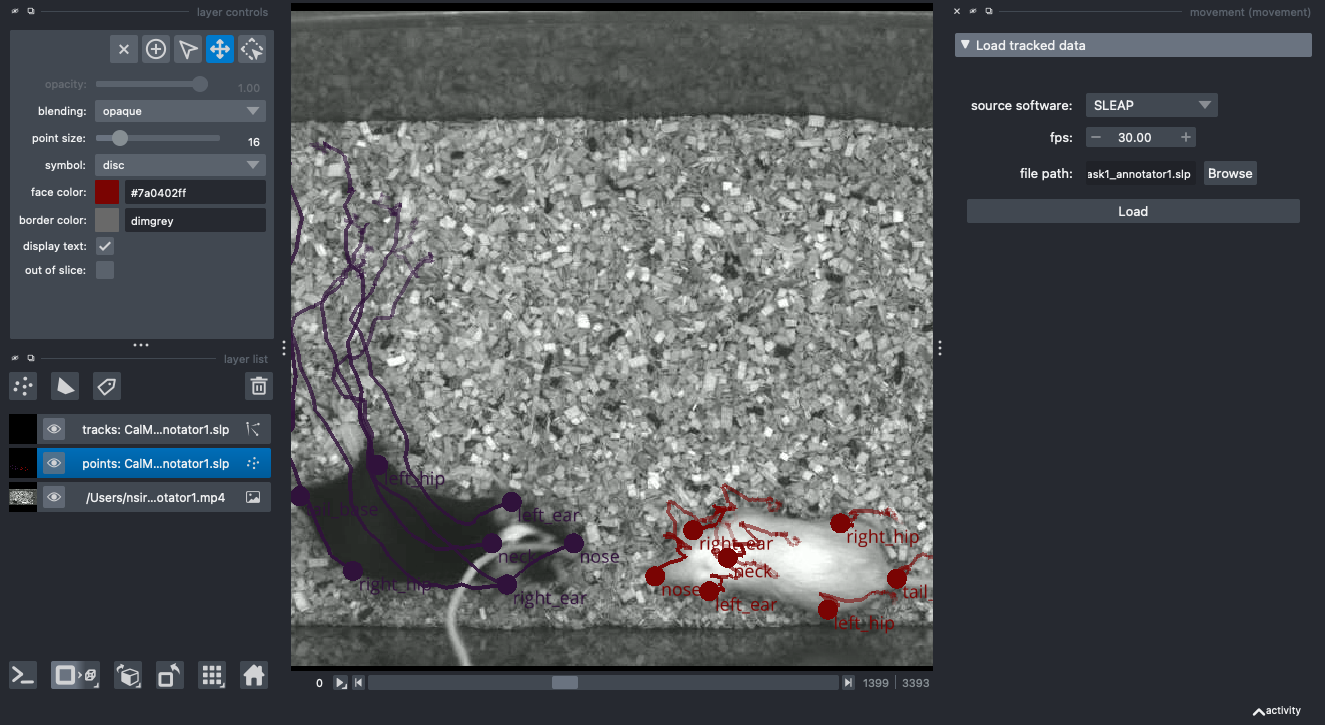
movement plugin for napari
After that you are free to play with the GUI on your own. You may try to explore the predictions you generated in Chapter 3, or any other tracking data you have at hand and is supported by movement.
Consult the GUI user guide in the movement documentation for more details.
In this section, we will walk through the tools movement offers for dealing with errors in motion tracking. These tools are implemented in the movement.filtering module and include functions for:
We will go through two notebooks from movement’s example gallery:
To run these examples as interactive Jupyter notebooks, you can go to end of each example and either:
.ipynb file in your code editor of choice (recommended), orFor this exercise you may continue working with the dataset you used to solve Exercise A in Section 4.3, or load another one. You should store each intermediate output as a data variable within the same dataset.
Refer to the filtering module documentation and to the examples we went through above.
Each filtering step involves selecting one or more parameters. We encourage you to experiment with different parameters values and inspect their effects by plotting the data.
We will work with the same “SLEAP_two-mice_octagon.analysis.h5” dataset we loaded in Section 4.2.1.
ds_oct = sample_data.fetch_dataset("SLEAP_two-mice_octagon.analysis.h5")
ds_oct<xarray.Dataset> Size: 2MB
Dimensions: (time: 9000, space: 2, keypoints: 7, individuals: 2)
Coordinates: (4)
Data variables:
position (time, space, keypoints, individuals) float32 1MB 796.5 ... nan
confidence (time, keypoints, individuals) float32 504kB 0.9292 ... 0.0
Attributes: (6)Consulting Figure 4.5, we decide on a confidence threshold of 0.8. This decision is always somewhat arbitrary, and confidence scores are not usually comparable across different tracking tools and datasets.
We can now drop the position values that are below the threshold:
from movement.filtering import (
filter_by_confidence,
rolling_filter,
interpolate_over_time,
)
confidence_threshold = 0.8
ds_oct["position_filtered"] = filter_by_confidence(
ds_oct.position,
ds_oct.confidence,
threshold=confidence_threshold,
print_report=True
)Missing points (marked as NaN) in input:
keypoints Nose EarLeft EarRight Neck BodyUpper BodyLower TailBase
individuals
1 107/9000 (1.19%) 9/9000 (0.1%) 9/9000 (0.1%) 9/9000 (0.1%) 9/9000 (0.1%) 9/9000 (0.1%) 44/9000 (0.49%)
2 272/9000 (3.02%) 260/9000 (2.89%) 260/9000 (2.89%) 260/9000 (2.89%) 260/9000 (2.89%) 260/9000 (2.89%) 392/9000 (4.36%)
Missing points (marked as NaN) in output:
keypoints Nose EarLeft EarRight Neck BodyUpper BodyLower TailBase
individuals
1 3972/9000 (44.13%) 1441/9000 (16.01%) 1200/9000 (13.33%) 390/9000 (4.33%) 9/9000 (0.1%) 520/9000 (5.78%) 3337/9000 (37.08%)
2 5143/9000 (57.14%) 1826/9000 (20.29%) 1324/9000 (14.71%) 489/9000 (5.43%) 524/9000 (5.82%) 1382/9000 (15.36%) 4899/9000 (54.43%)Smoothing the data with a rolling median filter:
ds_oct["position_smoothed"] = rolling_filter(
ds_oct.position_filtered,
window=5,
statistic="median",
min_periods=2,
print_report=True
)Missing points (marked as NaN) in input:
keypoints Nose EarLeft EarRight Neck BodyUpper BodyLower TailBase
individuals
1 3972/9000 (44.13%) 1441/9000 (16.01%) 1200/9000 (13.33%) 390/9000 (4.33%) 9/9000 (0.1%) 520/9000 (5.78%) 3337/9000 (37.08%)
2 5143/9000 (57.14%) 1826/9000 (20.29%) 1324/9000 (14.71%) 489/9000 (5.43%) 524/9000 (5.82%) 1382/9000 (15.36%) 4899/9000 (54.43%)
Missing points (marked as NaN) in output:
keypoints Nose EarLeft EarRight Neck BodyUpper BodyLower TailBase
individuals
1 3583/9000 (39.81%) 1196/9000 (13.29%) 1019/9000 (11.32%) 270/9000 (3.0%) 4/9000 (0.04%) 349/9000 (3.88%) 2821/9000 (31.34%)
2 4741/9000 (52.68%) 1493/9000 (16.59%) 994/9000 (11.04%) 314/9000 (3.49%) 341/9000 (3.79%) 970/9000 (10.78%) 4296/9000 (47.73%)Interpolating missing values across time:
ds_oct["position_interpolated"] = interpolate_over_time(
ds_oct.position_smoothed,
method="linear",
max_gap=10,
print_report=True
)Missing points (marked as NaN) in input:
keypoints Nose EarLeft EarRight Neck BodyUpper BodyLower TailBase
individuals
1 3583/9000 (39.81%) 1196/9000 (13.29%) 1019/9000 (11.32%) 270/9000 (3.0%) 4/9000 (0.04%) 349/9000 (3.88%) 2821/9000 (31.34%)
2 4741/9000 (52.68%) 1493/9000 (16.59%) 994/9000 (11.04%) 314/9000 (3.49%) 341/9000 (3.79%) 970/9000 (10.78%) 4296/9000 (47.73%)
Missing points (marked as NaN) in output:
keypoints Nose EarLeft EarRight Neck BodyUpper BodyLower TailBase
individuals
1 3394/9000 (37.71%) 1009/9000 (11.21%) 886/9000 (9.84%) 180/9000 (2.0%) 0/9000 (0.0%) 196/9000 (2.18%) 2456/9000 (27.29%)
2 4500/9000 (50.0%) 1263/9000 (14.03%) 750/9000 (8.33%) 162/9000 (1.8%) 205/9000 (2.28%) 670/9000 (7.44%) 3808/9000 (42.31%)The dataset now contains all intermediate processing steps.
ds_oct<xarray.Dataset> Size: 5MB
Dimensions: (time: 9000, space: 2, keypoints: 7, individuals: 2)
Coordinates: (4)
Data variables:
position (time, space, keypoints, individuals) float32 1MB ...
confidence (time, keypoints, individuals) float32 504kB 0.929...
position_filtered (time, space, keypoints, individuals) float32 1MB ...
position_smoothed (time, space, keypoints, individuals) float32 1MB ...
position_interpolated (time, space, keypoints, individuals) float32 1MB ...
Attributes: (6)We can even inspect the log of the final position data array:
print(ds_oct.position_interpolated.log)[
{
"operation": "filter_by_confidence",
"datetime": "2025-11-13 13:31:49.239462",
"confidence": "<xarray.DataArray 'confidence' (time: 9000, keypoints: 7, individuals: 2)> Size: 504kB\n0.9292 0.8582 0.9183 0.9426 0.9423 1.033 ... 0.8551 0.9173 0.598 0.8343 0.0\nCoordinates: (3)",
"threshold": "0.8",
"print_report": "True"
},
{
"operation": "rolling_filter",
"datetime": "2025-11-13 13:31:49.268658",
"window": "5",
"statistic": "'median'",
"min_periods": "2",
"print_report": "True"
},
{
"operation": "interpolate_over_time",
"datetime": "2025-11-13 13:31:49.753346",
"method": "'linear'",
"max_gap": "10",
"print_report": "True"
}
]Let’s pick a keypoint and plot its position across time for every processing step. To make the plotting a bit easier, we’ll stack the four position data arrays across a new dimension called step.
position_all_steps = xr.concat(
[
ds_oct.position,
ds_oct.position_filtered,
ds_oct.position_smoothed,
ds_oct.position_interpolated
],
dim="step"
).assign_coords(step=["original", "filtered", "smoothed", "interpolated"])
position_all_steps<xarray.DataArray 'position' (step: 4, time: 9000, space: 2, keypoints: 7,
individuals: 2)> Size: 4MB
796.5 724.5 812.8 721.0 816.9 704.9 821.1 ... 564.4 116.7 548.6 nan 539.9 nan
Coordinates: (5)Let’s plot the position of the EarLeft keypoint across time for every step.
position_all_steps.sel(individuals="1", keypoints="EarLeft").plot.line(
x="time", row="step", hue="space", aspect=2, size=2.5
)
plt.show()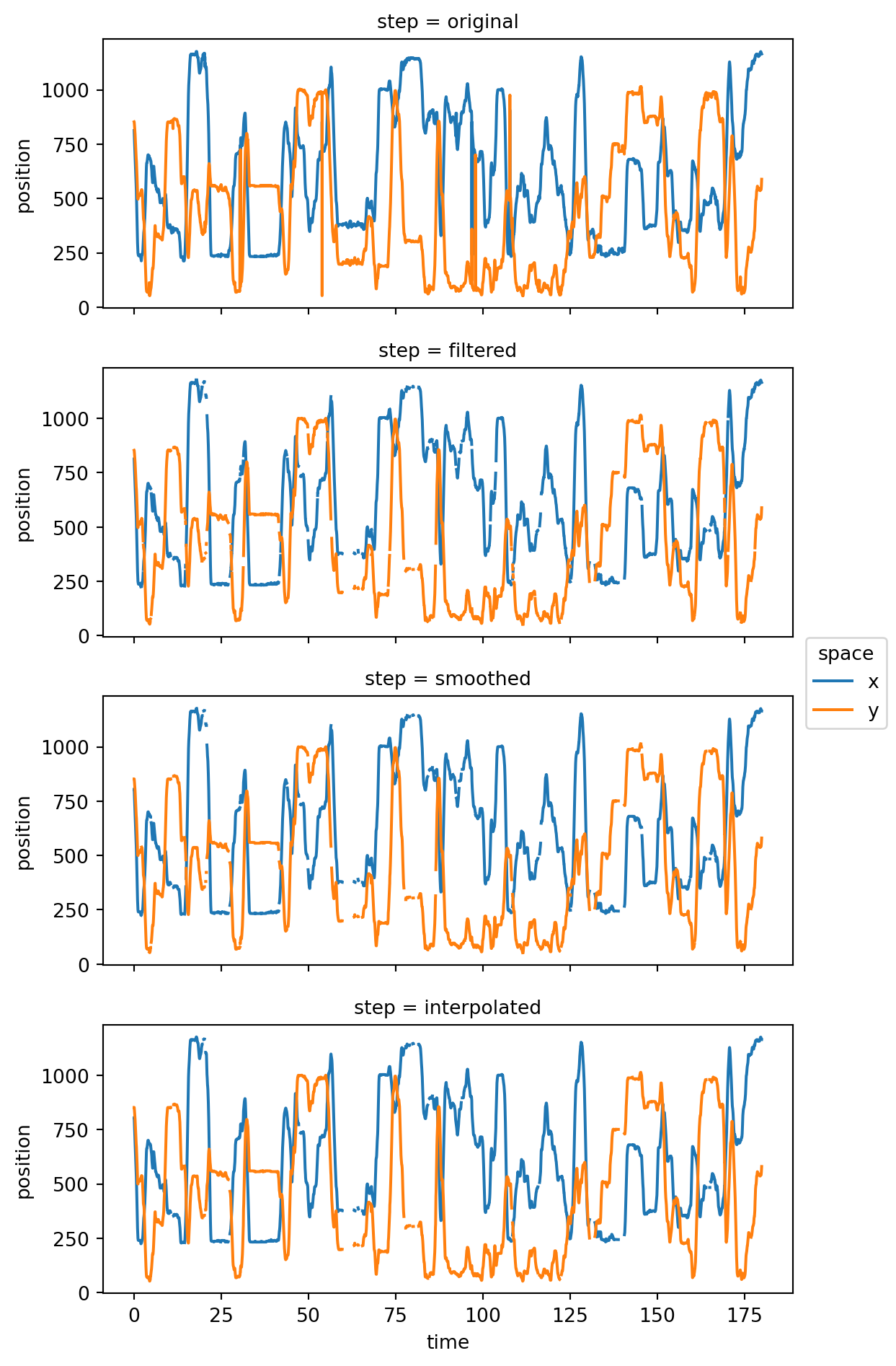
In this section, we will familiarise ourselves with the movement.kinematics module, which provides functions for deriving various useful quantities from motion tracks, such as velocity, acceleration, distances, orientations, and angles.
As in the previous section, we will go through a specific example from movement’s example gallery:
You can run this notebook interactively in the same way as in Section 4.5.
For this exercise you may continue working with the dataset you used to solve Exercise B in Section 4.5. In fact, you can use the fully processed position data as your starting point.
Refer to the kinematics module documentation and to the example we went through above.
We will continue working with the ds_oct from the previous exercise, using the position_interpolated data variable as our starting point.
Let’s first import the functions we will use:
from movement.kinematics import (
compute_speed,
compute_path_length,
compute_pairwise_distances,
)To compute the centroid position and speed:
ds_oct["centroid_position"] = ds_oct.position_interpolated.mean(dim="keypoints")
ds_oct["centroid_speed"] = compute_speed(ds_oct.centroid_position)
ds_oct.centroid_speed<xarray.DataArray 'centroid_speed' (time: 9000, individuals: 2)> Size: 72kB 401.3 23.79 384.8 41.19 508.6 73.54 629.7 ... 282.9 25.0 132.6 2.656 1.139 0.0 Coordinates: (2)
To plot it across time:
ds_oct.centroid_speed.plot.line(x="time", row="individuals", aspect=2, size=2.5)
plt.show()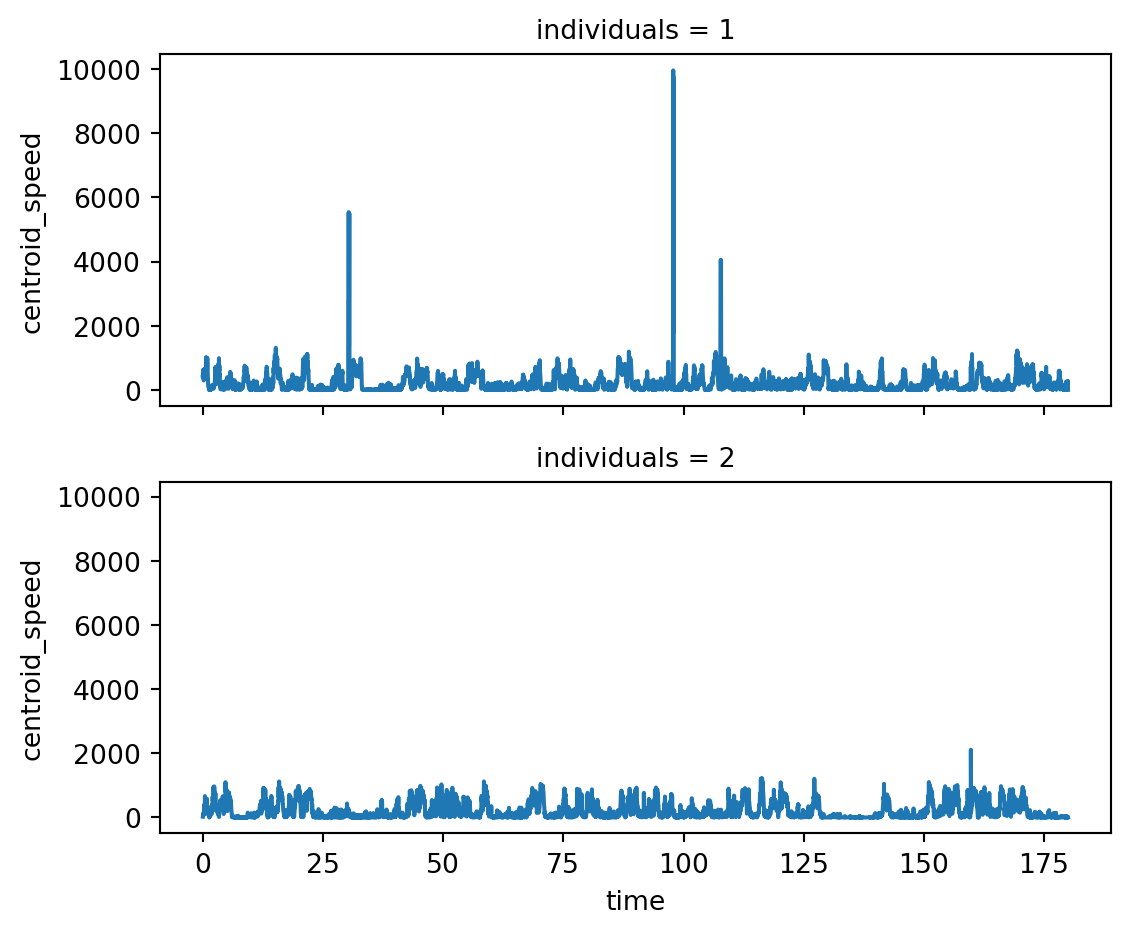
To compute the distance travelled by each individual within a certain time window:
ds_oct["path_length"] = compute_path_length(
ds_oct.centroid_position.sel(time=slice(50, 100))
)
ds_oct.path_length<xarray.DataArray 'path_length' (individuals: 2)> Size: 8B 1.047e+04 1.094e+04 Coordinates: (1) Attributes: (1)
We will compute the distance between the centroids of the two individuals and plot it across time:
ds_oct["inter_individual_distance"] = compute_pairwise_distances(
ds_oct.centroid_position,
dim="individuals",
pairs={"1": "2"}
)
ds_oct.inter_individual_distance<xarray.DataArray 'inter_individual_distance' (time: 9000)> Size: 72kB 177.2 172.2 168.7 162.3 159.0 157.3 ... 672.7 674.2 675.6 679.4 682.9 683.0 Coordinates: (1) Attributes: (1)
To plot the inter-individual distance across time:
ds_oct.inter_individual_distance.plot.line(x="time", aspect=2, size=2.5)
plt.show()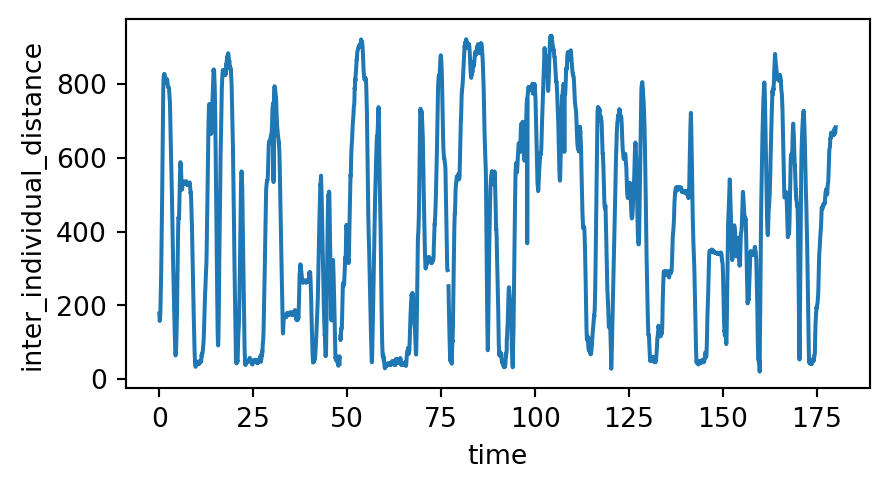
If you wish to learn more about quantifying motion with movement, including things we didn’t cover here, the following example notebooks are good follow-ups:
The following two chapters—Chapter 5 and Chapter 6—constitute case studies in which we apply movement to some real-world datasets. The two case studies represent quite different applications:
This chapter does not represent a full list of movement’s current and future capabilities. The package will continue to evolve as it’s being actively developed by a core team of engineers (aka the authors of this book) supported by a growing, global community of contributors.
We are committed to openness and transparency and always welcome feedback and contributions from the community, especially from practicing animal behaviour researchers, to shape the project’s direction.
Visit the movement community page to find about ways to get help and get involved.
movement package? What aspects of it could be improved?movement to support?If you have ideas, tell us about them on Zulip, open an issue on GitHub, or suggest a project for the hackday!